SQL Server’da İlişkili Tablolarda DISTINCT Kullanmadan Yinelenen Değerleri Kaldırmak

Herkese merhaba. Bu yazıda SQL Server’da ilişkili tablolarda DISTINCT kullanmadan yinelenen değerleri kaldırmak ile ilgili bilgi vermeye çalışacağım.
SQL Server’da verilerle çalıştığınızda, bazen veri girişleri nedeniyle değil, aynı zamanda T-SQL sorgularıyla da yinelenen veriler elde etme olasılıkları vardır. Çoğumuz DISTINCT anahtar sözcüğünü kullanır. DISTINCT kullanmak iyidir, bu yinelenen satırları kaldıracaktır. Ancak bazı durumlarda DISTINCT sorgu performansını iyileştirmez. Sorgu, yürütme için daha fazla zaman harcar ve daha fazla veriye sahipsek bu daha fazla zaman olacaktır.
ROW_NUMBER() kullanarak, sonuç kümesindeki yinelenen değerleri kaldırabiliriz. ROW_NUMBER(), sorgunun sonuç kümesindeki her satıra sıralı bir tamsayı numarası atayan bir fonksiyondur.
Aşağıda konuyla ilgili bir örnek görmektesiniz.
-- Bolumler tablosunu olusturma
CREATE TABLE Bolumler (
BolumID INT PRIMARY KEY,
BolumAdi VARCHAR(50)
);
-- Calisanlar tablosunu olusturma
CREATE TABLE Calisanlar (
CalisanID INT PRIMARY KEY,
Ad VARCHAR(50),
Soyad VARCHAR(50),
BolumID INT,
FOREIGN KEY (BolumID) REFERENCES Bolumler(BolumID)
);
-- Bolumler tablosuna ornek veri ekleme
INSERT INTO Bolumler (BolumID, BolumAdi)
VALUES (1, 'Satış'),
(2, 'Pazarlama'),
(3, 'Finans');
-- Calisanlar tablosuna ornek veri ekleme
INSERT INTO Calisanlar (CalisanID, Ad, Soyad, BolumID)
VALUES (1, 'Ahmet', 'Yılmaz', 1),
(2, 'Ayşe', 'Demir', 2),
(3, 'Mehmet', 'Kaya', 3),
(9, 'Ahmet', 'Yılmaz', 1),
(4, 'Elif', 'Öztürk', 1),
(5, 'Ali', 'Şahin', 2),
(6, 'Fatma', 'Arslan', 3),
(7, 'Ayşe', 'Demir', 2),
(8, 'Ahmet', 'Yılmaz', 1),
(10, 'Mehmet', 'Kaya', 3)
--Sorgu
WITH CTE AS (
SELECT AltSorgu.CalisanID
,AltSorgu.Ad
,AltSorgu.Soyad
,AltSorgu.BolumAdi
,ROW_NUMBER() OVER (PARTITION BY AltSorgu.Ad,AltSorgu.Soyad ORDER BY AltSorgu.CalisanID) AS rn
FROM (
SELECT t1.CalisanID
,t1.Ad
,t1.Soyad
,t2.BolumAdi
FROM Calisanlar t1
INNER JOIN Bolumler t2 ON t1.BolumID = t2.BolumID
) AS AltSorgu
)
SELECT CalisanID
,Ad
,Soyad
,BolumAdi
,rn
FROM CTE
WHERE rn = 1
ORDER BY CalisanID ASCYukarıdaki kodu çalıştırınca aşağıdakine benzer bir sonuç göreceksiniz.
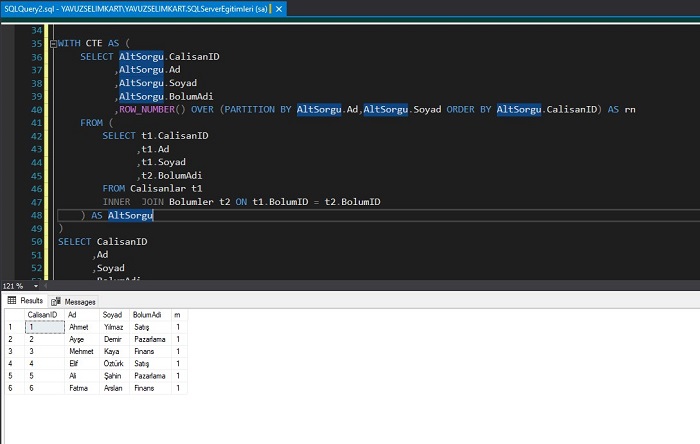
Görüldüğü üzere ilişkili tablolarda yinelenen satırlar kaldırılmış oldu.
Başka bir seçenek de, GROUP BY ifadesini kullanarak yinelenen değerleri kaldırmaktır. GROUP BY deyimi, aynı değerlere sahip satırları özet satırları halinde gruplandırır.
SELECT t1.Ad,
t1.Soyad,
t2.BolumAdi
FROM Calisanlar t1
INNER JOIN Bolumler t2
ON t1.BolumID = t2.BolumID
GROUP BY t1.Ad,
t1.Soyad,
t2.BolumAdi;Yukarıdaki kodu çalıştırınca aşağıdakine benzer bir sonuç göreceksiniz.
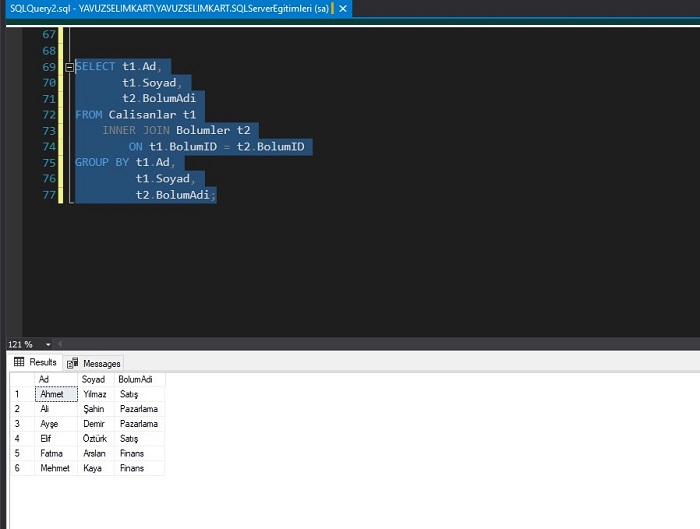
Görüldüğü üzere ilişkili tablolarda yinelenen satırlar tekrar kaldırılmış oldu.
Herkese çalışma hayatında ve yaşamında başarılar kolaylıklar.


